
基因组预测的序列数据在家畜育种中的应用
|
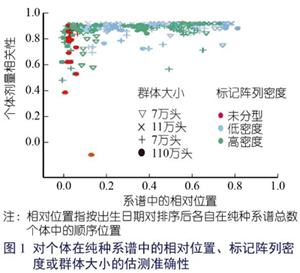
1.4 基因组的预测 我们在一个拥有3万个个体的品系中检测了基因组预测的准确性,这些个体的估测基因型为1 600万个SNPs。正如在AlphaBayes软件中预测的那样,使用岭回归( ridge regression)模型预测基因组。 利用该模式测试了22 318个个体,验证了1 458个个体。对9个具有不同遗传力和数量性状核苷酸(Quantitative Trait Nucleotides,QTN)的合成性状进行基因组预测。 使用4组标记进行基因组预测:从阵列中预选5.7万个标记(HD),从基于LD修剪的序列数据中预选24.8万个变体[全基因组测序(Whole Genome Sequencing,WGS)_LD,WGS_LD],从基于单标记回归结果[(WGS_基于总数据的孟德尔随机化(Summary data-based Mendelian Randomization,SMR),WGS_SMR]的序列数据中预选18.3万个变体,或通过仅每保留第200个变体(WGS_200)从该序列数据中预选6.7万个变体。基因组估计育种值(Genomic Estimated Breeding Value,gEBV)的准确性是根据该验证数据集中gEBV与合成表型之间的相关性来估计的。 2 结果和讨论 2.1 估测的准确性 对大多数受试个体而言,真实数据的估测精度较高(图1)。平均个体剂量相关性为0.94,中位数为0.97,四分位数范围为0.94~0.98。一些属于该纯种系谱最早几个世代的最古老的个体(位于系谱的前20%)具有很低的估测精度,因为它们无法提供其直系祖先的信息,或能够提供的信息极少,这影响了估测精度。 较晚几个世代的个体(位于系谱中前20%的后面)有更高的估测精度,平均剂量相关性为0.97,变异性更低:中位数为0.98,四分位数间距为0.96~0.99。 个体的标记阵列密度与用标记阵列基因分型获得的直系祖先的数量相矛盾,但对稍后几个世代的个体而言,标记阵列密度的HD和LD之间无显著差异,种群大小对估测精度的影响无明显的倾向性。 2.2 基因预测 在某些情况下,与标记阵列相比,序列数据能够提供更好的预测精度,但其优势取决于该性状的遗传结构。 |
上一篇:宠物兔如何引进种公种母?
下一篇:青海选育二十载牦牛有了新品种